들어가기전에…
과거부터 현재까지 기술 진보에 따른 산업의 패러다임의 변화가 있어 왔습니다. 증기기관의 발명으로 시작된 1차 산업혁명부터 21세기 4차 산업
혁명에 이르기까지 그 시대에 발전한 기술은 당시 살고 있는 사람들의 삶을 변화시킬만큼 큰 파급력을 발휘했습니다.
현재 우리는 4차 산업 혁명으로 정보 통신 기술 융합의 시대를 살고 있습니다. 이 4차 산업 혁명의 핵심 키워드로 사물 인터넷(Internet of Things; IoT)을 꼽을 수 있습니다.
사물인터넷이란 우리 주변의 사물들과 사람, 사물과 사물간에 정보를 인터넷을 기반으로하여 상호 소통하는 지능형 기술 및 서비스를 말합니다. 따라서 사물이 정보를 획득할 수 있는 센싱 기술, 인터넷 연결을 위한
통신 기술, 데이터 처리를 위한 빅데이터 기술의 융합이 필수적입니다. 수많은 사물로 부터 쏟아져 나오는 데이터를 효과적으로 수집하고 분석하는 것이 중요하며, 쏟아지는 데이터에서 의미있는 정보를 추출한다는 의미에서
4차 산업 혁명을 데이터 혁명이라고도 부릅니다. 거대 데이터 수집 및 분석을 위해서 풍부한 컴퓨팅 리소스를 활용할 수 있는 클라우드 컴퓨팅이 많이 이용되고 있으며, 이를 통해 초지능, 초연결의 가치를 극대화 할 수 있습니다.
이번 기고에서는 Raspberry PI의 온습도 센서, 메시지큐인 RabbitMQ 통해 센서로 부터 데이터를 수집하여 클라우드에 있는 시계열 DB에 저장하고, 이를 데이터 시각화 전문 대시보드인 Grafana를 통해 수집된 데이터를
그래프화하는 내용을 기술해보겠습니다.
Simple RabbitMQ Service란?
네이버 클라우드 플랫폼에서 제공하는 메시지 큐 서비스로 RabbitMQ가 설치된 클러스터를 제공하는 상품입니다.
이 서비스를 이용하여 RabbitMQ를 이용 시 기존 RabbitMQ 단일 노드가 가지고 있던 단일 장애점(SPOF) 문제를 해결할 수 있어 메시지 브로커의 장애로 인한 서비스 다운을 최소화 할 수 있습니다.
준비물
- Raspberry PI 3 모델 B
- DHT11 온습도 센서
- BreadBoard
- 5kΩ 저항
- 점퍼와이어
- GPIO 확장보드
- IDC 케이블
- 네이버 클라우드 플랫폼의 가상 머신 인스턴스
- 네이버 클라우드 플랫폼의 Simple RabbitMQ Service를 통해 생성한 RabbitMQ 클러스터
센서 부분
Raspberry PI는 USB, 이더넷, 영상출력 등의 기능을 가지고 있는 소형컴퓨터입니다. 이뿐만 아니라 입출력 신호를 제어할 수 있는 GPIO 포트를 내장하고 있어, 센서를 제어하고 이로 부터 데이터를 수신할 수 있습니다.
Raspberry PI의 GPIO를 통해서 DHT11 온습도 센서로 부터 데이터를 수집하고, Ncloud Simple RabbitMQ Service에서 생성한 RabbitMQ 서버의 데이터 수집 큐로 데이터를 전송하는 부분을 기술하겠습니다.
하드웨어 편
센서를 이용하기 위해서 가장 먼저 선행되어야 하는 작업은 데이터 시트를 확인하는 것입니다. 데이터 시트에는 센서의 스펙 및 이를 사용하기 위한 방법 등이 기술되어 있어 사용전 반드시 이를 확인해야 합니다.
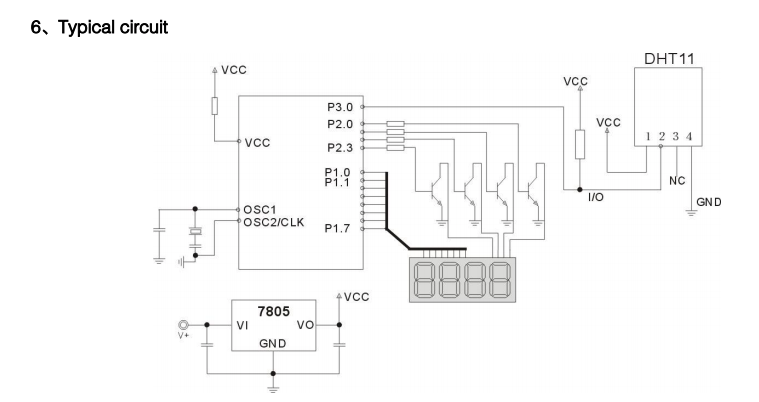
Typical Circuit 절을 통해서 1번핀은 전원 인가 부분 2번핀은 Data, 4번핀은 Ground에 연결해야함을 확인 할 수 있습니다.
2번 핀에 포트의 플로팅 상태를 방지하기 위한 풀업 저항 5kΩ을 구성해야함도 확인 할 수 있습니다.
이 정보를 바탕으로 BreadBoard에 회로를 구성해줍니다.

데이터를 수신하기 위한 GPIO 12번 포트에 DHT11의 데이터 핀과 연결하였습니다.
소프트웨어 편
NodeJS 설치
Raspberry PI는 ARM 기반의 프로세서를 탑재하고 있어, 일반적으로 PC보다 성능이 낮습니다.
보통 이러한 임베디드 프로그래밍을 C나 C++로 수행할때는, 크로스 컴파일러를 이용하여 PC에서 ARM용으로 빌드 후 이를 Raspberry PI에서 실행하는 방식으로 개발이 이루어집니다.
NodeJS를 이용하게 되면 ARM용 v8엔진 위에 Javascript 코드가 동작하기 때문에, 바이너리 파일 만들기 위한 빌드 과정이 필요가 없어 C, C++보다 빠른 결과물을 얻을 수 있습니다.
NodeJS 8 플랫폼으로 센서데이터를 수집하고 RabbitMQ로 쉽게 전송할 수 있습니다.
Raspberry PI에 NodeJS는 Node Version Manager(NVM)을 통해 설치 할 수 있습니다.
1 | # Install Node Version Manager (NVM) |
센서 데이터 수집 라이브러리 설치
센서 데이터 수집은 bcm2835 라이브러리를 이용하여 수집하였습니다.
이를 설치하는 방법은 다음과 같습니다.
1 | $ wget http://www.airspayce.com/mikem/bcm2835/bcm2835-1.52.tar.gz |
센서 데이터 수집 코드 구현
index.js1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32require('dotenv').config();
const sensorLib = require("node-dht-sensor");
const rabbitmq = require('./helpers/rabbitmq');
rabbitmq.connect();
const sensor = {
initialize: () => {
return sensorLib.initialize(11, 12);
},
read: ( callback ) => {
const data = sensorLib.read();
// const data = sensorLib.read(this.sensors[0].type, this.sensors[0].pin);
callback({
temperature: data.temperature.toFixed(1),
humidity: data.humidity.toFixed(1),
})
}
};
if ( sensor.initialize() ) {
setInterval(() => {
sensor.read(( data ) => {
console.log( data.temperature + "°C, " + data.humidity + "%");
rabbitmq.sendData({ queueName: 'sensor_queue', data })
});
}, 2000);
} else {
console.warn('Failed to initialize sensor');
}
bcm2835 라이브러리를 이용하면 센서 초기화 및 수집된 데이터를 쉽게 10진수 형태로 변환할 수 있습니다.sensor.initialize()함수를 호출하여 센서 초기화가 성공하면, 2초 간격으로 데이터를 읽고 이를 RabbitMQ의 sensor_queue큐로 보냅니다.
helpers/rabbitmq/index.js1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44const amqp = require('amqplib/callback_api');
const {
RABBITMQ_HOST: hostname,
RABBITMQ_PORT: port,
RABBITMQ_USER: username,
RABBITMQ_PASS: password,
} = process.env;
let conn = null;
module.exports = {
connect: ( callback ) => {
amqp.connect({
protocol: 'amqp',
hostname,
port,
username,
password,
locale: 'en_US',
vhost: '/'
}, (error, connection) => {
if ( error ) {
return callback(error);
} // end if
conn = connection;
if ( callback ) callback(null);
});
},
receiveData: ({ queueName }, callback) => {
/** **/
},
sendData: ({ queueName, data }) => {
conn.createChannel((err, ch) => {
if ( err ) {
return console.log( err );
}
ch.sendToQueue(queueName, new Buffer( JSON.stringify( data )));
});
}
};
RabbitMQ의 큐에 데이터를 쓰기 위해서는, connection과 channel 객체를 획득해야합니다.
이후 channel의 sendToQueue 메서드를 통해 데이터를 전송할 수 있습니다. 데이터를 전송전에 JSON.stringify()를 통해
직렬화를 한 후 이를 버퍼에 담아 전송합니다.
서버 부분
NodeJS 서버에서는 센서가 RabbitMQ의 sensor_queue로 보낸 데이터를 수신하여, 시계열 데이터 베이스인 InfluxDB에 저장하는 역할을 수행합니다.
그리고 시계열 DB에 저장된 데이터들은 Grafana를 통해 수집된 데이터를 그래프로 나타낼 수 있습니다.
server.js1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31require('dotenv').config();
const influx = require('./helpers/influx').connect();
const rabbitmq = require('./helpers/rabbitmq');
rabbitmq.connect(( error ) => {
if ( error ) {
return console.log( error );
} // end if
rabbitmq.receiveData({ queueName: 'sensor_queue'}, async ( data ) => {
const {
temperature, humidity
} = data;
console.log( data );
await influx.writePoints([
{
measurement: 'sensor_data',
tags: { sensor: 'thermometer' },
fields: { value: parseFloat(temperature) },
},
{
measurement: 'sensor_data',
tags: { sensor: 'hygrometer' },
fields: { value: parseFloat(humidity) },
}
])
});
});
NodeJS서버에서는 RabbitMQ 서버에 접속하여 sensor_queue의 데이터를 가져와, 이를 시계열 데이터 베이스인 InfluxDB에 기록하는 역할을 수행합니다.
Grafana에서 InfluxDB에 저장된 내용을 그래프로 시각화할 수 있습니다.
환경 구축
NodeJS서버, InfluxDB, Grafana의 3가지 앱이 필요합니다.
Docker Container을 사용하면 이 세가지 환경을 쉽게 구축할 수 있습니다.
Docker 설치
아래 명령어를 통해 Docker 최신버전을 설치 할 수 있습니다.1
$ curl -fsSL https://get.docker.com/ | sh
컨테이너 실행
Docker 설치 후 위에서 기술한 3가지 앱을 실행합니다.
1 | # InfluxDB 실행 |
Grafana 데이터 시각화
Grafana 대시보드에 접속하기 위해, VM에 공인 아이피를 부여합니다. http://[공인IP]:3000 URL을 통해 접속 할 수 있습니다.

초기 아이디와 비밀번호를 입력하고 Home으로 이동합니다.
데이터 소스 선택을 위해 Add Data Source버튼을 클릭합니다.

Docker의 link옵션을 통해 influxDB와 연결되어 있습니다. Access 타입을 Proxy로 선택하고 나머지 사항을 입력합니다.

Data Source 선택후 시각화할 데이터 타입으로 Graph를 선택합니다.

Grafana는 데이터 조회를 위한 쿼리를 클릭 몇번으로 손쉽게 만들 수 있습니다. 위 그림과 같이 입력하면, 실시간으로 수집된 데이터를 시각화할 수 있습니다.

나머지 습도 또한 위와 유사한 방법으로 시각화 할 수 있습니다.
이번 기고에서는 클라우드 컴퓨팅과 연계하여 저장공간의 한계가 있는 소형컴퓨팅의 한계를 극복하고 또 이를 시각화하여 데이터 추이를 확인 할 수 있는
정보 가공을 다루어 보았습니다.
수많은 데이터가 생성되는 정보의 호수 속에 AI 등의 기술로 유용한 정보를 찾아내어 사람의 실생활에 도움이 되는 변화를 주고자하는 시도가 매우 활발히 일어 나고 있습니다.
네이버 클라우드 플랫폼이 이러한 발걸음의 밑거름이 되길 바라며 글을 마칩니다.
이번 기고에서 작성된 코드는 아래의 Github Repository에서 확인 할 수 있습니다.
国内查看评论需要代理~